It's just as well people can understand speech. Imagine if you were like a computer: friends would have to "talk" to you by
prodding away at a plastic keyboard connected to your brain by a
long, curly wire. If you wanted to say "hello" to someone, you'd
have to reach out, chatter your fingers over their keyboard,
and wait for their eyes to light up; they'd have to do the same to
you. Conversations would be a long, slow, elaborate nightmare—a
silent dance of fingers on plastic; strange, abstract, and remote.
We'd never put up with such clumsiness as humans, so why do we talk
to our computers this way?
Scientists have long dreamed of building machines that
can chatter and listen just like humans. But although computerized
speech recognition has been around for decades, and is now built
into most smartphones and PCs, few of us actually use it. Why?
Possibly because we never even bother to try it out, working on the
assumption that computers could never pull off a trick so complex as
understanding the human voice. It's certainly true that speech
recognition is a complex problem that's challenged some of the
world's best computer scientists, mathematicians, and linguists. How
well are they doing at cracking the problem? Will we all be chatting
to our PCs one day soon? Let's take a closer look and find out!
Photo: A court reporter dictates notes into a laptop with a
noise-cancelling
microphone and speech-recogition software. Photo by Micha Pierce courtesy of
US Marine Corps and DVIDS.
Language sets people far above our creeping, crawling animal
friends. While the more intelligent creatures, such as dogs and
dolphins, certainly know how to communicate with sounds, only humans
enjoy the rich complexity of language. With just a couple of dozen
letters, we can build any number of words (most dictionaries contain
tens of thousands) and express an infinite number of thoughts.
Photo: Speech recognition has been popping up all over the place for quite a few years now.
Even my old iPod Touch (dating from around 2012) has a built-in "voice control" program that let you pick out music just by saying "Play albums by U2," or whatever band you're in the mood for.
When we speak, our voices generate little sound packets called
phones (which correspond to the sounds of letters or groups of
letters in words); so speaking the word cat produces phones that correspond
to the sounds "c," "a," and "t." Although you've probably never heard
of these kinds of phones before, you might well be familiar with the
related concept of phonemes: simply speaking, phonemes are the
basic LEGO™ blocks of sound that all words are built from.
Although the difference between phones and phonemes is complex and
can be very confusing, this is one "quick-and-dirty" way to
remember it: phones are actual bits of sound that we speak
(real, concrete things), whereas phonemes are ideal bits of
sound we store (in some sense) in our minds (abstract, theoretical
sound fragments that are never actually spoken).
Computers and computer models can juggle around with phonemes, but
the real bits of speech they analyze always involves processing
phones. When we listen to speech, our ears catch phones flying
through the air and our leaping brains flip them back into words,
sentences, thoughts, and ideas—so quickly, that we often know what
people are going to say before the words have fully fled from their
mouths. Instant, easy, and quite dazzling, our amazing brains make
this seem like a magic trick. And it's perhaps because listening
seems so easy to us that we think computers (in many ways even more
amazing than brains) should be able to hear, recognize, and decode
spoken words as well. If only it were that simple!
Sponsored links
Why is speech so hard to handle?
The trouble is, listening is much harder than it looks (or
sounds): there are all sorts of different problems going on at the same
time...
When someone speaks to you in the street, there's the sheer
difficulty of separating their words (what scientists would call the
acoustic signal) from the background noise—especially
in something like a cocktail party, where the "noise" is
similar speech from other conversations.
When people talk quickly, and run all their words together in a long stream, how do we know
exactly when one word ends and the next one begins? (Did they just
say "dancing and smile" or "dance, sing, and smile"?)
There's the problem of how everyone's voice is a little bit
different, and the way our voices change from moment to moment. How
do our brains figure out that a word like "bird" means exactly
the same thing when it's trilled by a ten year-old girl or boomed by
her forty-year-old father?
What about words like "red" and "read" that sound identical but mean totally different things (homophones,
as they're called)? How does our brain know which word the speaker
means?
What about sentences that are misheard to mean radically
different things? There's the age-old military example of "send
reinforcements, we're going to advance" being misheard for "send
three and fourpence, we're going to a dance"—and all of us can
probably think of song lyrics we've hilariously misunderstood the
same way (I always chuckle when I hear Kate Bush singing about "the
cattle burning over your shoulder").
On top of all that stuff, there are issues like
syntax (the grammatical structure of language) and semantics (the
meaning of words) and how they help our brain decode the words we
hear, as we hear them. Weighing up all these factors, it's easy to
see that recognizing and understanding spoken words in real time (as
people speak to us) is an astonishing demonstration of blistering
brainpower.
It shouldn't surprise or disappoint us that computers struggle to
pull off the same dazzling tricks as our brains; it's
quite amazing that they get anywhere near!
Photo: Using a headset microphone like this makes a huge difference to the accuracy of speech recognition: it reduces background sound, making it much easier for the computer to separate the signal (the all-important words you're speaking) from the noise (everything else).
How do computers recognize speech?
Speech recognition is one of the most complex areas of computer
science—and partly because it's interdisciplinary: it involves a mixture of
extremely complex linguistics, mathematics, and computing itself. If
you read through some of the technical and scientific papers that have been published
in this area (a few are listed in the references below), you may well
struggle to make sense of the complexity. My
objective is to give a rough flavor of how computers recognize
speech, so—without any apology whatsoever—I'm going to simplify
hugely and miss out most of the details.
Broadly speaking, there are four different approaches a computer
can take if it wants to turn spoken sounds into written words:
Simple pattern matching (where each spoken word is recognized in its
entirety—the way you instantly recognize a tree or a table without
consciously analyzing what you're looking at)
Pattern and feature
analysis (where each word is broken into bits and recognized from key
features, such as the vowels it contains)
Language modeling and statistical analysis (in which a knowledge of grammar and the
probability of certain words or sounds following on from one another is
used to speed up recognition and improve accuracy)
Artificial neural networks (brain-like computer models that can reliably
recognize patterns, such as word sounds, after exhaustive training).
In practice, the everyday speech recognition we encounter in things
like automated call centers, computer dictation software, or
smartphone "agents" (like Siri and Cortana) combines a variety
of different approaches. For the purposes of understanding clearly how things work,
however, it's best to keep things quite separate and think
about them one at a time.
1: Simple pattern matching
Ironically, the simplest kind of speech recognition isn't really
anything of the sort. You'll have encountered it if you've ever
phoned an automated call center and been answered by a computerized
switchboard. Utility companies often have systems like this that you
can use to leave meter readings, and banks sometimes use them to
automate basic services like balance inquiries, statement orders,
checkbook requests, and so on. You simply dial a number, wait for a
recorded voice to answer, then either key in or speak your account
number before pressing more keys (or speaking again) to select what
you want to do. Crucially, all you ever get to do is choose one
option from a very short list, so the computer at the other end never
has to do anything as complex as parsing a sentence (splitting
a string of spoken sound into separate words and figuring out their
structure), much less trying to understand it; it needs no knowledge
of syntax (language structure) or semantics (meaning). In other words, systems like this aren't really recognizing speech at all: they simply have to be able to distinguish
between ten different sound patterns (the spoken words zero through
nine) either using the bleeping sounds of a Touch-Tone phone keypad
(technically called DTMF) or the spoken sounds of your voice.
From a computational point of view, there's not a huge difference
between recognizing phone tones and spoken numbers "zero", "one,"
"two," and so on: in each case, the system could solve the problem by
comparing an entire chunk of sound to similar stored patterns in its memory.
It's true that there can be quite a bit of variability in how different people say
"three" or "four" (they'll speak in a different tone, more or
less slowly, with different amounts of background noise) but the ten
numbers are sufficiently different from one another for this not to
present a huge computational challenge. And if the system can't
figure out what you're saying, it's easy enough for the call to be
transferred automatically to a human operator.
Photo: Voice-activated dialing on cellphones is little more than simple pattern matching. You simply train the phone to recognize the spoken version of a name in your phonebook. When you say a name, the phone doesn't do any particularly sophisticated analysis; it simply compares the sound pattern with ones you've stored previously and picks the best match.
No big deal—which explains why even an old phone like this 2001 Motorola could do it.
2: Pattern and feature analysis
Automated switchboard systems generally work very reliably because
they have such tiny vocabularies: usually, just ten words
representing the ten basic digits. The vocabulary that a speech
system works with is sometimes called its domain. Early speech
systems were often optimized to work within very specific domains,
such as transcribing doctor's notes, computer programming commands,
or legal jargon, which made the speech recognition problem far
simpler (because the vocabulary was smaller and technical terms
were explicitly trained beforehand). Much like humans, modern
speech recognition programs are so good that they work in any domain
and can recognize tens of thousands of different words. How do they
do it?
Most of us have relatively large vocabularies, made from hundreds
of common words ("a," "the," "but" and so on, which we
hear many times each day) and thousands of less common ones (like
"discombobulate," "crepuscular," "balderdash," or
whatever, which we might not hear from one year to the next).
Theoretically, you could train a speech recognition system to
understand any number of different words, just like an automated
switchboard: all you'd need to do would be to get your speaker to
read each word three or four times into a microphone, until the
computer generalized the sound pattern into something it could
recognize reliably.
The trouble with this approach is that it's hugely inefficient.
Why learn to recognize every word in the dictionary when all those
words are built from the same basic set of sounds? No-one wants to
buy an off-the-shelf computer dictation system only to find they have
to read three or four times through a dictionary, training it up to
recognize every possible word they might ever speak, before they can
do anything useful. So what's the alternative? How do humans
do it? We don't need to have seen every Ford, Chevrolet, and Cadillac
ever manufactured to recognize that an unknown, four-wheeled vehicle
is a car: having seen many examples of cars throughout our
lives, our brains somehow store what's called a prototype (the
generalized concept of a car, something with four wheels, big enough
to carry two to four passengers, that creeps down a road) and we
figure out that an object we've never seen before is a car by
comparing it with the prototype. In much the same way, we don't need
to have heard every person on Earth read every word in the dictionary
before we can understand what they're saying; somehow we can
recognize words by analyzing the key features (or components) of the
sounds we hear. Speech recognition systems take the same approach.
The recognition process
Practical speech recognition systems start by listening to a chunk
of sound (technically called an utterance) read through a
microphone. The first step involves digitizing the sound (so the
up-and-down, analog wiggle of the sound waves is turned into
digital format, a string of numbers) by a piece of hardware
(or software) called an analog-to-digital (A/D) converter
(for a basic introduction, see our article on analog
versus digital technology). The
digital data is converted into a spectrogram (a graph
showing how the component frequencies of the sound change in
intensity over time) using a mathematical technique called a Fast Fourier Transform (FFT)),
then broken into a series of overlapping chunks called acoustic
frames, each one typically lasting 1/25 to 1/50 of a second. These are digitally
processed in various ways and analyzed to find the components of
speech they contain. Assuming we've separated the utterance into words,
and identified the key features of each one, all we have to do is compare
what we have with a phonetic dictionary (a list of known words
and the sound fragments or features from which they're made)
and we can identify what's probably been said.
Probably is always the word in speech
recognition: no-one but the
speaker can ever know exactly what was said.)
Sponsored links
Seeing speech
Speech recognition programs start by turning utterances into a spectrogram:
It's a three-dimensional graph:
Time is shown on the horizontal axis, flowing from left to right
Frequency is on the vertical axis, running from bottom to top
Energy is shown by the color of the chart, which indicates how much energy there is in each frequency of the sound at a given time.
In this example, I've sung three distinct tones into a microphone, each one lasting about 5–10 seconds, with a bit of silence in between. The first one, shown by the small red area on the left, is the trace for a quiet, low-frequency sound. That's why the graph shows dark colors (reds and purples) concentrated in the bottom of the screen. The second tone, in the middle, is a similar tone to the first but quite a bit louder (which is why the colors appear a bit brighter). The third tone, on the right, has both a higher frequency and intensity. So the trace goes higher up the screen (higher frequencies) and the colors are brighter (more energy).
With a fair bit of practice, you could recognize what someone is saying just by looking at a diagram like this; indeed, it was once believed that deaf and hearing-impaired people might be trained to use spectrograms to help them decode words they couldn't hear.
In theory, since spoken languages are built from only a few dozen
phonemes (English uses about 46, while Spanish has only about 24),
you could recognize any possible spoken utterance just by learning to
pick out phones (or similar key features of spoken language such as
formants, which are prominent frequencies that can be used to
help identify vowels). Instead of having to recognize the sounds of
(maybe) 40,000 words, you'd only need to recognize the 46 basic
component sounds (or however many there are in your language), though
you'd still need a large phonetic dictionary listing the
phonemes that make up each word. This method of analyzing
spoken words by identifying phones or phonemes is often called the
beads-on-a-string model: a chunk of unknown speech (the
string) is recognized by breaking it into phones or bits of phones
(the beads); figure out the phones and you can figure out the words.
Most speech recognition programs get better as you use them
because they learn as they go along using feedback you give
them, either deliberately (by correcting mistakes) or by default
(if you don't correct any mistakes, you're effectively saying everything was
recognized perfectly—which is also feedback). If you've ever used a program like one of the
Dragon dictation systems, you'll be familiar with the way you have to
correct your errors straight away to ensure the program continues to
work with high accuracy. If you don't correct mistakes, the program
assumes it's recognized everything correctly, which means similar
mistakes are even more likely to happen next time. If you force the
system to go back and tell it which words it should have chosen, it
will associate those corrected words with the sounds it heard—and
do much better next time.
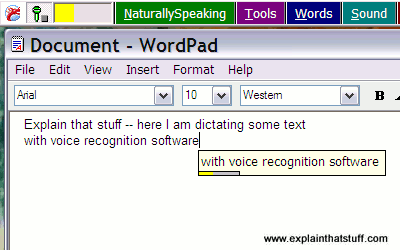
Screenshot: With speech dictation programs like Dragon NaturallySpeaking, shown here,
it's important to go back and correct your mistakes if you want your words to be recognized accurately in future.
3: Statistical analysis
In practice, recognizing speech is much more complex than simply
identifying phones and comparing them to stored patterns, and for a
whole variety of reasons:
Speech is extremely variable: different people speak in different ways (even though we're all
saying the same words and, theoretically, they're all built from a
standard set of phonemes)
You don't always pronounce a certain word in exactly the same way; even if you did, the way you spoke a word
(or even part of a word) might vary depending on the sounds or words that came before or after.
As a speaker's vocabulary grows, the number of similar-sounding
words grows too: the digits zero through nine all sound different
when you speak them, but "zero" sounds like "hero," "one"
sounds like "none," "two" could mean "two," "to," or
"too"... and so on. So recognizing numbers is a tougher job for
voice dictation on a PC, with a general 50,000-word vocabulary, than
for an automated switchboard with a very specific, 10-word vocabulary
containing only the ten digits.
The more speakers a system has to
recognize, the more variability it's going to encounter and the
bigger the likelihood of making mistakes.
For something like an
off-the-shelf voice dictation program (one that listens to your voice
and types your words on the screen), simple pattern recognition is
clearly going to be a bit hit and miss. The basic principle of
recognizing speech by identifying its component parts certainly holds
good, but we can do an even better job of it by taking into account
how language really works. In other words, we need to use what's
called a language model.
When people speak, they're not simply muttering a series of random
sounds. Every word you utter depends on the words that come before or
after. For example, unless you're a contrary kind of poet, the word
"example" is much more likely to follow words like "for,"
"an," "better," "good", "bad," and so on than words
like "octopus," "table," or even the word "example"
itself. Rules of grammar make it unlikely that a noun like "table"
will be spoken before another noun ("table example" isn't
something we say) while—in English at least—adjectives ("red," "good," "clear")
come before nouns and not after them ("good example" is far more
probable than "example good"). If a computer is trying to
figure out some spoken text and gets as far as hearing "here is a
******* example," it can be reasonably confident that ******* is an
adjective and not a noun. So it can use the rules of grammar to
exclude nouns like "table" and the probability of pairs like
"good example" and "bad example" to make an intelligent
guess. If it's already identified a "g" sound instead of a "b",
that's an added clue.
Virtually all modern speech recognition systems also use a bit of
complex statistical hocus-pocus to help figure out what's being said.
The probability of one phone following another, the probability of
bits of silence occurring in between phones, and the likelihood of
different words following other words are all factored in.
Ultimately, the system builds what's called a
hidden Markov model
(HMM) of each speech segment, which is the computer's best guess at
which beads are sitting on the string, based on all the things it's
managed to glean from the sound spectrum and all the bits and pieces
of phones and silence that it might reasonably contain. It's called a
Markov model (or Markov chain), for Russian mathematician
Andrey Markov, because it's a sequence of different things (bits of phones, words, or whatever) that change from one
to the next with a certain probability. Confusingly, it's
referred to as a "hidden" Markov model even though it's worked out in
great detail and anything but hidden! "Hidden,"
in this case, simply means the contents of the model aren't observed directly but
figured out indirectly from the sound spectrum. From the computer's viewpoint, speech recognition is
always a probabilistic "best guess" and the right answer can never be known until the speaker
either accepts or corrects the words that have been recognized.
(Markov models can be processed with an extra bit of computer jiggery pokery called
the Viterbi algorithm,
but that's beyond the scope of this article.)
4: Artificial neural networks
HMMs have dominated speech recognition since the 1970s—for the
simple reason that they work so well. But they're by no means the
only technique we can use for recognizing speech. There's no reason
to believe that the brain itself uses anything like a hidden Markov
model. It's much more likely that we figure out what's being said
using dense layers of brain cells that excite and suppress one
another in intricate, interlinked ways according to the input signals
they receive from our cochleas (the parts of our inner ear that
recognize different sound frequencies).
Back in the 1980s, computer scientists developed "connectionist"
computer models that could mimic how the brain learns to recognize patterns,
which became known as artificial neural networks (sometimes
called ANNs). A few speech recognition scientists explored using
neural networks, but the dominance and effectiveness of HMMs
relegated alternative approaches like this to the sidelines. More
recently, scientists have explored using ANNs and HMMs side by side
and found they give significantly higher accuracy over HMMs used
alone.
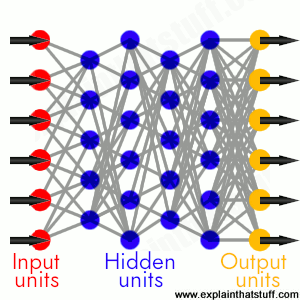
Artwork: Neural networks are hugely simplified, computerized versions of the brain—or a tiny part of it that have inputs (where you feed in information), outputs (where results appear), and hidden units (connecting the two). If you train them with enough examples, they learn by gradually adjusting the strength of the connections between the different layers of units. Once a neural network is fully trained, if you show it an unknown example, it will attempt to recognize what it is based on the examples it's seen before.
Speech recognition: a summary
Artwork: A summary of some of the key stages of speech recognition and the computational processes happening behind the scenes.
This artwork is a very quick summary of what we've explored so far. The blocks down the center represent
the path we follow from hearing an unknown bit of speech (at the top) to confidently declaring what we think has been said (at the bottom). It's a very general summary; not all speech recognition involves all these stages, in this exact order.
The colored ovals down the sides represent some of the key computational processes that get us from unknown
utterance to recognized speech. Again, not all of these are used in every speech recognition system, they don't always happen in this order, and there are quite a few other things I've missed out (in an effort to keep my explanation reasonably short and simple). Generally speaking, though, the processes happen where I've positioned them. So the analog to digital and Fast Fourier Transform (FFT) stages happen quite early on, while the Hidden Markov Model (HMM) is built later. User feedback happens at the very end and corrects not just the recognized words but also things like the phonetic dictionary (how a certain speaker pronounces each word) or feature analysis program (each speaker will pronounce different things in different ways).
Importantly, speech recognition software often works recursively (repeatedly moving back and forth) rather than in a single pass from the first word to the last. It's a bit like solving a crossword puzzle. The more clues you fill in, the more information you have, and the more constraints there are on the remaining clues. Equally, you may need to revisit some of your early answers, which turn out to be inconsistent with things you find out later. The closer you get to the end of a complete sentence, the easier it is to identify mistakes in the grammar or the syntax—and those could also force you to revisit your guesses at the earlier words in the sentence. In short, there's a lot of back-and-forth in speech recognition: the computational processes work in parallel, and "cooperate," to give the most accurate guess at the words in the spoken utterance.
Sponsored links
What can we use speech recognition for?
We've already touched on a few of the more common applications of
speech recognition, including automated telephone switchboards and
computerized voice dictation systems. But there are plenty more
examples where those came from.
Many of us (whether we know it or not) have cellphones with voice
recognition built into them. Back in the late 1990s, state-of-the-art
mobile phones offered voice-activated dialing,
where, in effect, you recorded a sound snippet for each entry
in your phonebook, such as the spoken word "Home," or whatever
that the phone could then recognize when you spoke it in future. A
few years later, systems like SpinVox became popular helping mobile
phone users make sense of voice messages by converting them
automatically into text (although a
sneaky BBC investigation eventually claimed that some of its state-of-the-art speech automated
speech recognition was actually being done by humans in developing
countries!).
Today's smartphones make speech recognition even more of a feature.
Apple's Siri,
Google Assistant
("Hey Google..."), and Microsoft's Cortana are smartphone "personal assistant apps" who'll listen to what you say, figure out what you mean, then
attempt to do what you ask, whether it's looking up a phone number or
booking a table at a local restaurant. They work by linking speech
recognition to complex natural language processing (NLP) systems, so they can figure out not just what you say, but what you
actually mean, and what you really want to happen as a
consequence. Pressed for time and hurtling down the street, mobile
users theoretically find this kind of system a boon—at least if you
believe the hype in the TV advertisements that Google and Microsoft
have been running to promote their systems. (Google quietly incorporated speech recognition into its search engine some time ago, so you can Google just by talking to your smartphone, if you really want to.)
If you have one of the latest voice-powered electronic assistants, such as Amazon's Echo/Alexa or Google Home, you don't need a computer of any kind (desktop, tablet, or smartphone): you just ask questions
or give simple commands in your natural language to a thing that resembles a
loudspeaker... and it answers straight back.
Screenshot: When I asked Google "does speech recognition really work," it took it three attempts to recognize the question correctly.
Will speech recognition ever take off?
I'm a huge fan of speech recognition. After suffering with
repetitive strain injury on and off for some time, I've been using
computer dictation to write quite a lot of my stuff for about 15
years, and it's been amazing to see the improvements in off-the-shelf
voice dictation over that time.
The early Dragon NaturallySpeaking system I used on a Windows 95 laptop was fairly reliable, but I had to speak
relatively slowly, pausing slightly between each word or word group,
giving a horribly staccato style that tended to interrupt my train of
thought. This slow, tedious one-word-at-a-time approach ("can –
you – tell – what – I – am – saying – to – you") went
by the name discrete speech recognition. A few years later,
things had improved so much that virtually all the off-the-shelf
programs like Dragon were offering continuous speech recognition,
which meant I could speak at normal speed, in a normal way, and still
be assured of very accurate word recognition. When you can speak
normally to your computer, at a normal talking pace, voice dictation
programs offer another advantage: they give clumsy, self-conscious
writers a much more attractive, conversational style: "write like
you speak" (always a good tip for writers) is easy to put into
practice when you speak all your words as you write them!
Despite the technological advances, I still generally prefer to
write with a keyboard and
mouse. Ironically, I'm writing this article
that way now. Why? Partly because it's what I'm used to. I often
write highly technical stuff with a complex vocabulary that I know
will defeat the best efforts of all those hidden Markov models and
neural networks battling away inside my PC. It's easier to type
"hidden Markov model" than to mutter those words somewhat
hesitantly, watch "hiccup half a puddle" pop up on screen and
then have to make corrections.
Screenshot: You an always add more words to a speech recognition program. Here, I've decided to train the Microsoft Windows built-in speech recognition engine to spot the words 'hidden Markov model.'
Mobile revolution?
You might think mobile devices—with their slippery touchscreens—would benefit enormously from speech recognition:
no-one really wants to type an essay with two thumbs on a pop-up QWERTY keyboard.
Ironically, mobile devices are heavily used by younger,
tech-savvy kids who still prefer typing and pawing at screens to speaking
out loud.
Why? All sorts of reasons, from sheer familiarity (it's
quick to type once you're used to it—and faster
than fixing a computer's goofed-up guesses) to privacy and consideration for others (many of us
use our mobile phones in public places and we don't want our thoughts wide open to scrutiny
or howls of derision), and the sheer difficulty of speaking clearly
and being clearly understood in noisy environments.
Recently, I was walking down a street and overheard a small garden party where the sounds of
happy laughter, drinking, and discreet background music were punctuated by a
sudden grunt of "Alexa play Copacabana by Barry Manilow"—which silenced
the conversation entirely and seemed jarringly out of place.
Speech recognition has never been so indiscreet.
What you're doing with your computer also makes a difference. If you've ever used
speech recognition on a PC, you'll know that writing something
like an essay (dictating hundreds or thousands of words of ordinary
text) is a whole lot easier than editing it afterwards (where
you laboriously try to select words or sentences and move them up or
down so many lines with awkward cut and paste commands). And trying
to open and close windows, start programs, or navigate around a
computer screen by voice alone is clumsy, tedious, error-prone, and
slow. It's far easier just to click your mouse or swipe your finger.
Photo: Here I'm using Google's Live Transcribe app to dictate the last paragraph of this article. As you can see, apart from the punctuation, the transcription is flawless, without any training at all. This is the fastest and most accurate speech recognition software I've ever used. It's mainly designed as an accessibility aid for deaf and hard of hearing people, but it can be used for dictation too.
Developers of speech recognition systems insist everything's about
to change, largely thanks to natural language processing and smart
search engines that can understand spoken queries. ("OK Google...")
But people have been saying that for decades now: the brave new
world is always just around the corner. According to speech pioneer James Baker,
better speech recognition "would greatly increase the speed and ease with which humans could
communicate with computers, and greatly speed and ease the ability
with which humans could record and organize their own words and
thoughts"—but he wrote (or perhaps voice dictated?) those words 25 years ago!
Just because Google can now understand speech, it doesn't follow that we automatically want
to speak our queries rather than type them—especially when you consider some of
the wacky things people look for online.
Humans didn't invent written language because others struggled to hear
and understand what they were
saying. Writing and speaking serve different purposes. Writing is a
way to set out longer, more clearly expressed and elaborated thoughts
without having to worry about the limitations of your short-term
memory; speaking is much more off-the-cuff.
Writing is grammatical; speech doesn't always play by the rules.
Writing is introverted, intimate, and inherently private; it's carefully and thoughtfully composed.
Speaking is an altogether different way of expressing your thoughts—and people don't always want to
speak their minds. While technology may be ever advancing, it's far
from certain that speech recognition will ever take off in quite the
way that its developers would like. I'm typing these words, after
all, not speaking them.
Sponsored links
Don't want to read our articles? Try listening instead
Statistical Methods for Speech Recognition by Frederick Jelinek. MIT Press, 1997. A detailed guide to Hidden Markov Models and the other statistical techniques that computers use to figure out human speech.
Fundamentals of Speech Recognition by Lawrence R. Rabiner and Biing-Hwang Juang. PTR Prentice Hall, 1993. A little dated now, but still a good introduction to the basic concepts.
The Holy Grail of Speech Recognition by Janie Chang: Microsoft Research, 29 August 2011. How neural networks are making a comeback in speech recognition research. [Archived via the Wayback Machine.]
How Siri Works: Interview with Tom Gruber by Nova Spivack, Minding the Planet, 26 January 2010. Gruber explains some of the technical tricks that allow Siri to understand natural language.
Speech Recognition by Computer by Stephen E. Levinson and Mark Y. Liberman, Scientific American,
Vol. 244, No. 4 (April 1981), pp. 64–77. A more detailed overview of the basic concepts.
A good article to continue with after you've read mine.
More technical
An All-Neural On-Device Speech Recognizer by Johan Schalkwyk, Google AI Blog, March 12, 2019. Google announces a state-of-the-art speech recognition system based entirely on what are called recurrent neural network transducers (RNN-Ts).
Improving End-to-End Models For Speech Recognition by Tara N. Sainath, and Yonghui Wu, Google Research Blog, December 14, 2017. A cutting-edge speech recognition model that integrates traditionally separate aspects of speech recognition into a single system.
Speech Recognition Technology: A Critique by Stephen E. Levinson, Proceedings of the National Academy of Sciences of the United States of America. Vol. 92, No. 22, October 24, 1995, pp.
9953–9955.
Patents set out the technical gritty of how inventions work. There are dozens covering different kinds of speech recognition; here are a few representative examples:
A Historical Perspective of Speech Recognition by Raj Reddy (an AI researcher at Carnegie Mellon), James Baker (founder of Dragon), and Xuedong Huang (of Microsoft). Speech recognition pioneers look back on the advances they helped to inspire in this four-minute discussion.
Please do NOT copy our articles onto blogs and other websites
Articles from this website are registered at the US Copyright Office. Copying or otherwise using registered works without permission, removing this or other copyright notices, and/or infringing related rights could make you liable to severe civil or criminal penalties.